
Logica fuzzy este o formă de logică de control ce imită raționamentul uman prin gestionarea informațiilor imprecise sau incerte.
Spre deosebire de logica binară tradițională ( utilizată pentru optimizarea traficului curent ) , care operează pe valori adevărat/fals (1/0), logica fuzzy lucrează cu grade de adevăr, permițând sistemelor de control să fie mai flexibile și adaptive.
În optimizarea semnalelor de trafic, tehnologia de control fuzzy este folosită pentru a gestiona semnalele într-un mod care se adaptează la condițiile de trafic în timp real. De exemplu, un sistem de control fuzzy poate ajusta lungimea luminilor verzi bazându-se pe densități variabile de trafic, reducând destul de eficient congestia rutieră.
Acest lucru este posibil datorită considerării simultane a mai mulți factori, cum ar fi lungimea cozii de vehicule, viteza traficului și momentul zilei, pe baza acesteia se iau decizii nuanțate pe care sistemele tradiționale de logică binară nu le pot face.
Structura logicii fuzzy ( supranumită și logică vagă ):
Structura unui controler oricare ( nu neapărat acest exemplu ) de logică fuzzy (FLC) constă din mai multe componente cheie care lucrează împreună pentru a procesa intrările, a aplica regulile de logică fuzzy și a genera ieșiri. Figura de mai jos demonstrează comparația sistemului de logică .
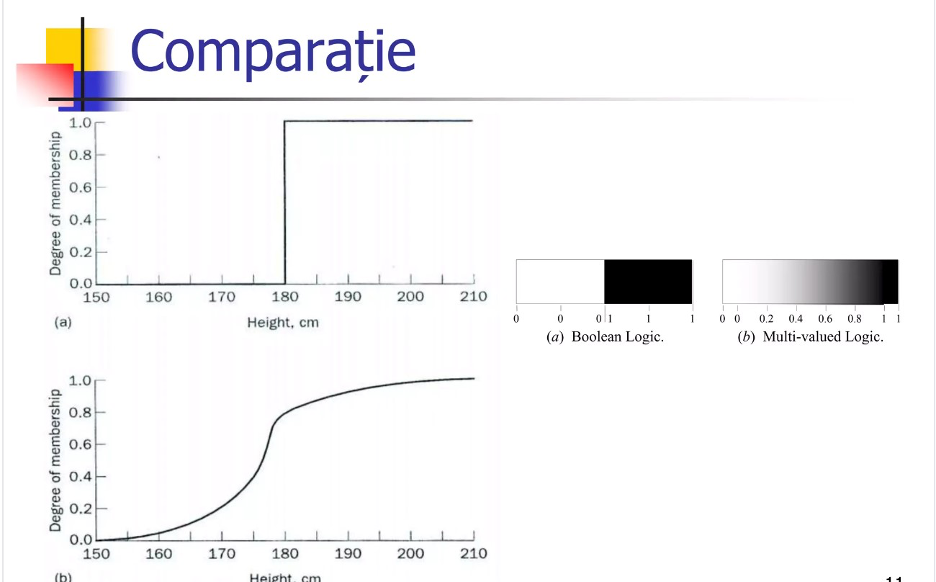
Fuzzificare: fuzzificarea într-un controler de logică de tip fuzzy transformă intrările precise, precum numărul de vehicule, viteza, lungimea cozii și timpul de așteptare, în alte valori fuzzy pe care sistemul le poate interpreta și utiliza pentru luarea deciziilor. Acest proces implică utilizarea funcțiilor de apartenență pentru a categoria datele de intrare în termeni lingvistici precum „scăzut”, „mediu” sau „ridicat”.
În timpul fuzzificării, o valoare de intrare în timp real cum ar fi timpul sau numărul de vehicule este comparată cu aceste funcții de apartenență predefinite pentru a genera valori de intrare fuzzy.
Aceste valori fuzzy sunt apoi utilizate pentru procesare ulterioară în controlerul de logică fuzzy.
• Bază de cunoștințe
Baza de cunoștințe într-un controler de logică fuzzy este compusă din două componente principale: Baza de reguli și Baza de date.
Baza de reguli conține un set de reguli fuzzy „dacă-atunci” care ghidează procesul de luare a deciziilor pentru gestionarea semafoarelor pe baza intrărilor .
De exemplu, o regulă ar putea stipula: „Dacă numărul de vehicule este ridicat și viteza este mică, atunci extinde durata luminii verzi”.
Aceste reguli permit sistemului să răspundă la condiții variabile de trafic într-un mod flexibil și adaptiv.
Baza de date stochează funcțiile de apartenență care definesc modul în care valorile de intrare sunt fuzzificate și defuzzificate, oferind datele esențiale necesare pentru a converti intrările din lumea reală în valori fuzzy și înapoi în ieșiri precise.
Luate împreună, baza de reguli și baza de date formează nucleul capacității de luare a deciziilor a sistemului de logică fuzzy.
• Defuzzificare
Etapa de defuzzificare este pasul în care ieșirile fuzzy de la un controler de logică fuzzy sunt convertite în numere specifice care pot fi folosite pentru a controla semafoarele.
Această etapă decide timpul exact în care un semafor ar trebui să rămână verde, galben sau roșu pe baza condițiilor actuale de trafic. Două metode comune pentru a face acest lucru sunt metodele Centroid și Maximum:
— Metoda CENTROID
Controlerul calculează „centrul de greutate” al ieșirii fuzzy, care oferă un număr echilibrat prin luarea în considerare a tuturor opțiunilor posibile.
De exemplu, după ce analizează densitatea și viteza traficului, ar putea sugera menținerea luminii verzi aprinse timp de 37 de secunde.
— Metoda MAXIMUM
Alege ieșirea cu cel mai înalt nivel de certitudine sau adevăr. De exemplu, dacă „45 de secunde” este durata cea mai sigură sau probabilă pe baza regulilor, o alege pe aceasta.
Ambele metode ajută la convertirea regulilor fuzzy în acțiuni clare pentru a gestiona eficient semafoarele, îmbunătățind fluxul de trafic și reducând congestionarea.
2.2.3 Învățarea automată
Învățarea Automată (Machine Learning – ML) este practic un subdomeniu al inteligenței artificiale care se concentrează pe dezvoltarea de algoritmi și modele care permit calculatoarelor să învețe din date și să își îmbunătățească performanța în timp, fără programare explicită.
Conform lui Michie et al. (1994), Învățarea Automată implică metode de calcul-automate care învață o sarcină dintr-o serie de exemple, bazându-se pe operații logice sau binare. Scopul este de a construi modele care pot clasifica, prezice sau lua decizii pe baza datelor, iar aceste modele devin mai precise pe măsură ce sunt expuse la mai multe exemple ( diferite )[44].
• Învățarea Automată în managementul traficului
Învățarea Automată (ML) a revoluționat sistemele de management al traficului curent ( în unele țări ) prin permiterea deciziilor bazate pe date care se pot ajusta dinamic la condițiile în timp real. Aplicarea ML în managementul traficului se concentrează pe valorificarea datelor pentru a prezice condițiile de trafic, a optimiza sistemele de control al traficului, a detecta anomalii și a oferi perspective pentru o planificare și siguranță mai bună.
Această secțiune explorează doar cele trei ramuri majore ale ML, ce pot fi utilizate în managementul traficului: învățarea supervizată, învățarea nesupervizată și învățarea prin întărire (Reinforcement Learning – RL).
a. Învățarea supervizată
Învățarea supervizată implică antrenarea unui model pe un set de date etichetat, unde datele de intrare sunt asociate cu ieșirea corectă.
Scopul este ca modelul să învețe mapping-ul dintre intrări și ieșiri, astfel încât să poată face predicții precise pe date noi, nevăzute.
În managementul traficului, învățarea supervizată este utilizată pe scară largă pentru sarcini precum predicția fluxului de trafic, estimarea vitezei, detectarea accidentelor și clasificarea vehiculelor.
Predicția fluxului de trafic este crucială pentru gestionarea congestionării și optimizarea timpilor semafoarelor.
Algoritmii de învățare supervizată, precum Regresia Liniară, Arborii de Decizie și Mașinile cu Vectori de Susținere (SVM), sunt tehnici utilizate în mod obișnuit pentru acest scop. Cu alte cuvinte, acești algoritmi sunt antrenați pe date istorice de trafic (volumul traficului, viteza și densitatea) pentru a prezice condițiile viitoare de trafic.
De exemplu, un model de trafic aleatoriu poate învăța din tiparele datelor de trafic din trecut pentru a anticipa numărul de vehicule care vor trece printr-o intersecție într-un interval de timp specific. Astfel sistemele de management al traficului pot prezice și ajusta proactiv timpii semafoarelor pentru a minimiza problema majoră – congestia.
- Regresia liniară este unul dintre cele mai simple modele, ce pot fi folosite pentru a prezice fluxul de trafic. Presupune o relație liniară între volumul traficului și diverse caracteristici de intrare, cum ar fi momentul zilei, condițiile meteo și fluxul de trafic anterior.
- Arborii de decizie și trafic aleatoriu oferă un mecanism de predicție mai precis. Arborii de decizie împart datele în ramuri bazate pe valorile caracteristicilor, conducând la un rezultat aproape de exact. Traficul aleatoriu este o metodă de ansamblu a mai multor arbori de decizie, meniți să reducă ,,supraînvățarea,, și îmbunătățesc generalizarea prin combinarea ieșirilor diferiților arbori.
- Mașinile cu vectori de susținere (SVM) sunt folosite pentru predicția fluxului de trafic, prin găsirea hiperplanului care separă cel mai bine punctele de date ale diferitelor condiții de trafic. SVM-urile funcționează bine cu date de înaltă dimensiune, astfel pot gestiona eficient relațiile neliniare, făcându-le potrivite pentru scenarii de trafic complexe.
b. Învățarea nesupervizată
Este un alt tip de învățare automată în care nu se folosesc etichete manuale ale intrărilor. Se distinge de abordările de învățare supervizată, care învață cum se îndeplinește o sarcină utilizând tehnici precum clasificarea sau regresia, folosind un set de exemple pregătite de om [6].
Există mai multe tipuri diferite de algoritmi de învățare nesupervizată, inclusiv algoritmi de clustering, algoritmi de reducere a dimensionalității și algoritmi de estimare a densității.
Algoritmii de clustering sunt utilizați pentru a grupa puncte de date similare, cum ar fi gruparea clienților pe baza istoricului lor de achiziții.
Algoritmii de reducere a dimensionalității sunt folosiți pentru a reduce numărul de variabile dintr-un set de date, păstrând structura acestuia. Algoritmii de estimare a densității sunt utilizați pentru a estima funcția de densitate de probabilitate a unui set de date, ceea ce poate fi util pentru detectarea anomaliilor.[45][46]
• Învățarea nesupervizată în managementul traficului
Este utilizată în mod obișnuit pentru clusteringul tiparelor de trafic, detectarea anomaliilor și înțelegerea structurii subiacente a datelor de trafic.
Potrivit SUMO – tehnicile de învățare automată nesupervizată s-au dovedit eficiente în prezicerea și gestionarea fluxului de trafic în rețele urbane mari.
Spre deosebire de învățarea supervizată, învățarea nesupervizată nu necesită date etichetate, permițând identificarea tiparelor și structurilor ascunse în date.
Una dintre cele mai populare metode de învățare nesupervizată este clusteringul, care grupează puncte de date similare pe baza proximității lor. În managementul traficului, clusteringul ajută la identificarea zonelor congestionate și a blocajelor, permițând inginerilor de trafic să optimizeze fluxul, astfel reducând aglomerația.
O altă aplicație cheie a învățării nesupervizate în managementul traficului este detectarea anomaliilor, cum ar fi accidentele, închiderile de drumuri sau ambuteiajele neașteptate, cele ce se abat semnificativ de la tiparele normale de trafic.
Algoritmi precum auto-encoderii și Analiza Componentelor Principale (PCA) pot învăța comportamentul normal al unui sistem de trafic și pot detecta abaterile, permițând planificatorilor de trafic ( Ingineri – Urbaniști ) să ia măsuri proactive pentru a gestiona aceste anomalii. Algoritmi bazați pe grafuri, precum clusteringul spectral și detectarea punctelor comune, pot identifica noduri și muchii importante în rețeaua de trafic, relevând structuri și clustere ascunse care pot fi optimizate pentru a îmbunătăți fluxul de trafic.
În plus, învățarea nesupervizată poate modela evoluția fluxului de trafic în timp, folosind tehnici precum analiza seriilor temporale și modelarea rețelelor dinamice. Acest lucru ajută la prezicerea viitoarelor puncte de aglomerație și la identificarea potențialelor blocaje.
Punctul forte al învățării nesupervizate constă în capacitatea sa de a detecta tipare subiacente în seturi de date complexe, cum ar fi influența condițiilor rutiere, a momentului zilei, a vremii și a comportamentului neașteptat a șoferilor asupra fluxului de trafic.
Prin gruparea segmentelor de drum similare și reducerea complexității problemei, învățarea nesupervizată îmbunătățește optimizarea fluxului de trafic, făcându-l mai eficient și mai puțin predispus la congestie.
c. Învățarea prin întărire
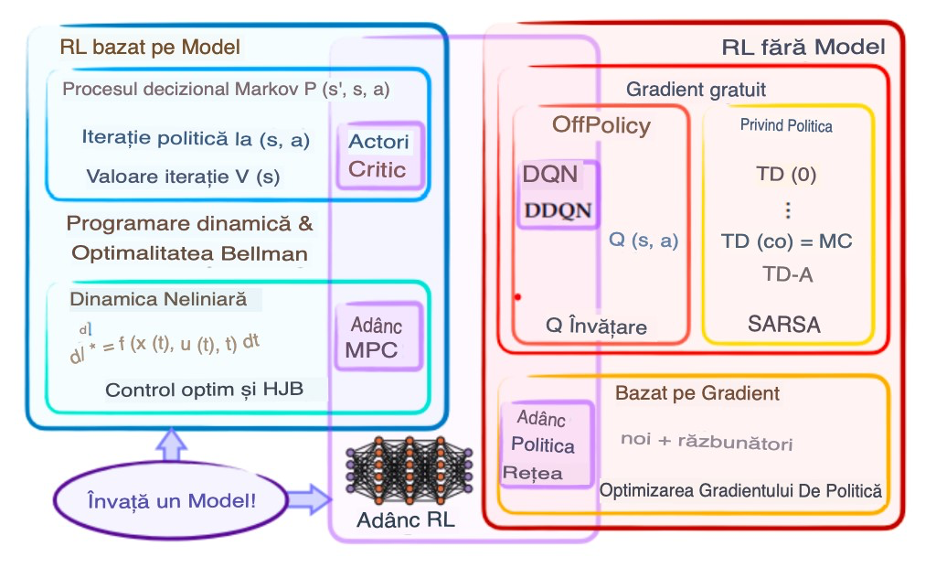
Învățarea prin Întărire (Reinforcement Learning – RL) este un tip de învățare automată, o tehnică mai complexă decât Machine Learning, trăsătură distinctă a conceptelor IA, învață prin interacțiunea cu mediul său. Un agent RL începe fără cunoștințe prealabile despre ce acțiuni să întreprindă. Explorează mediul și primește un semnal de recompensă, r, bazat pe rezultatele acțiunilor sale. Această recompensă poate fi pozitivă sau negativă, menită să ajute agentul să învețe treptat până ajunge în epoca cu cele mai bune acțiuni de întreprins.
Agentul trebuie să echilibreze între exploatarea acțiunilor cunoscute care oferă recompense bune și explorarea de noi acțiuni pentru a găsi opțiuni potențial mai bune. În RL, valorile Q reprezintă recompensa așteptată pentru fiecare acțiune posibilă într-o anumită stare, ghidând agentul să facă cele mai bune alegeri. Aceste valori Q sunt de obicei stocate într-o matrice care reflectă experiența învățată a agentului.
Tehnicile RL sunt clasificate în două categorii principale, bazate pe model și fără model, diferențiind dacă agentul are acces la un model al mediului sau nu, așa cum este demonstrat în (Figura de mai jos).
Leave A Comment